Data Puzzles are synthetically generated datasets with some embedded patterns. Patterns have various forms from relationships between attributes to rules of the form “if condition then value” between specific attribute-value pairs. These patterns are stochastic and embedded in datasets using DataMaker - our Data Puzzle Generation Tool.
We use data puzzles extensively in the class assignments. These range from data exploration and plotting through hypothesis testing to prediction and machine learning. After the assignment is completed we reveal the data secrets - the patterns which were embedded by DataMaker. Students do not have to find exactly the embedded patterns, often they find related patterns which makes the “game” even more fun.
In the following we provide the list of data puzzles along with the underlying data sets. Using DataMaker we change the patterns and even data sets from academic year to academic year.. We can also provide data puzzles of different levels of difficulty from the one star (easy) to five star (most difficult) ones.
We will now proceed to nine datasets -first seven of them are synthetically created by DataMaker data puzzles with embedded secret patterns. Last two are real data sets - airbnb and titanic. Each data set is subject of a separate subsection 10.2-10.10. These sections are structured in a similar way. We start each section with around eight to ten practice snippets and follow with the Code Roulette link, where we randomly select a small coding task for students using the data set of this section. We provide the output which requested code returns when run on the data set. But we do not provide the code. This has to be written by a student.
Each section 10.i starts with the snippet “Get to know your data”. There are around fifteen R instructions there when executed return the column set of the data set, number of rows, summary of the data set, unique values of each attribute and various basic distributions.
For example, the first section, 10.2 starts with the following “Get to know your data” snippet. These are repeated for all 9 data sets. Here we explain each line below.
colnames(moody)
# returns all columns of moody
summary(moody)
# provides summary, distributions of different columns of moody
nrow(moody)
# returns number of rows of moody
unique(moody$GRADE)
#provides unique values of GRADE attribute (grades)
unique(moody$DOZES_OFF)
#provides unique values of DOZES_OFF attribute (‘always’, ‘sometimes’, ‘never’)
unique(moody$TEXTING_IN_CLASS)
#provides unique values of TEXTING_IN_CLASS) attribute (‘always’, ‘sometimes’, ‘never’)
table(moody$GRADE)
#Frequency distribution of GRADE
table(moody$DOZES_OFF)
#Frequency distribution ofDOZES_OFF
table(moody$TEXTING_IN_CLASS)
#Frequency distribution of TEXTING_IN_CLASS
tapply(moody$SCORE, moody$GRADE, mean)
#Provides a mean score for each of the grades. We expect it will be diminishing with the grade
tapply(moody$PARTICIPATION, moody$GRADE, mean)
#Provides mean participation for each of the grades. We do not know what to expect. Perhaps it will be diminishing with the grade
tapply(moody$SCORE, moody$DOZES_OFF, mean)
#Provides a mean score for each of the values of DOZES_OFF. We do not know what to expect. Perhaps it will be diminishing the more often a student DOZES_OFF?
tapply(moody$PARTICIPATION, moody$DOZES_OFF, mean)
#Provides mean participation for each of the values of DOZES_OFF. We do not know what to expect. Perhaps it will be diminishing the more often a student DOZES_OFF?
After we get to know the data, we follow with the number of simple coding tasks - some of them are:
Exploratory queries - compute mean, max, min on a subset of the data set
Hypothesis testing for difference of means of numerical attribute of the data set
Calculation of posterior odds using Odd’s formulation of Bayes Theorem.
Hypothesis testing for test of independence
14.2 Strange grading methods of Professor Moody Data Puzzle
How to get a good grade in Professor Moody’s class?
Professor Moody does not give final grades just on the basis of your total score alone. Our data shows that two students with the same total score may get widely varying final grades. Can you believe that you can even fail his class with a score as high as 82%? This is outrageous, isn’t it?
DataMaker has generated thousands of tuples which in addition to the total score and final grade also store bizarre information about student behaviors in the class - do they often doze off? Does a student text a lot? Does s/he ask a lot of questions? Does it help if you ask a lot of questions? Does it hurt if you doze off a lot?
Table 14.1: Snippet of Moody Dataset
SCORE
GRADE
DOZES_OFF
TEXTING_IN_CLASS
PARTICIPATION
21.33
F
never
never
0.29
71.57
C
always
rarely
0.11
90.11
A
always
never
0.26
31.52
D
sometimes
rarely
0.03
95.94
A
always
rarely
0.21
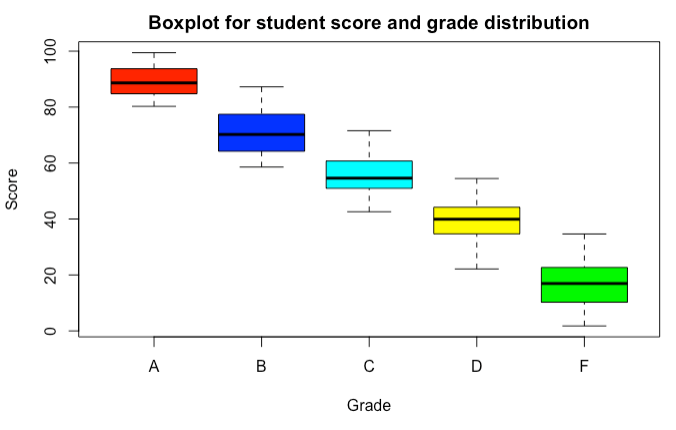
Figiure 1: Boxplot for student score and grade distribution 14.2.2.9
14.2.1 🧙 Secret patterns embedded by the Data Maker (hint)
It is not surprising that Professor Moody does not like when students text in his class all the time. He also does not like the sleepers - who doze off and do not participate at all. But….if they do well in class nevertheless, and have convincing scores, he has no choice but give them grades their score imply. However, if one has a border score, could be B, could be A, or can be B or can be C, then Moody apparently weights in the sleeping/texting data!
Always texting in class or always dozing off in class makes a difference but only for border line scores. That is, for scores between 80 and 90, the grade will be a B when Texting_inclass = ‘always’ or Dozing_off =’always”. Situation is similar for border scores between C and B and F and D.
Check it out!
14.2.2 Practice Snippets
14.2.2.1 Snippet 1: Get familiar with the data set
Q: What gives a higher chance of failing, texting all the time or always dozing off during class? A: Always texting in class! Almost 40% chance of failing!
Q: Verify the hypothesis that C students have higher mean participation than F students? What is the p-value? A: Negative. Fail to reject null hypothesis that mean participations of C and F students are the same with p=0.11
Q: What is the mean score of students who always doze off in class and what is the most frequent grade that they received? A: The mean score is 50.26 and the most frequent grade is D.
Great job!! You have made it this far. You are now familiar with the moody dataset and it’s time to give your understanding a test. Please click the link below to get to the quiz and come back here to cross-check your answer in the snippet 14.2.4.
14.2.2.9 Snippet 9
Visualizing the grade w.r.t score for the moody dataset.
DataMaker has generated data about thousands of parties, some fun parties, others which were OK or simply boring. Your goal is to discover secrets of a fun party. Is it music? Dancing? Does the host matter? Or who was present at a party? Maybe who was NOT present at the party? All this data is stored in this data puzzle.
Table 14.2: Snippet of Party Dataset
Party
Music
Host
WasThere
WasNotThere
CaloriesDanc
477
Fun
None
Janek
Janusz
Joe
339
1616
Boring
Classical
Xi
Billy
Manny
104
3195
Fun
HipHop
Alex
Janusz
Manny
220
1358
Fun
None
Janek
Janusz
Vladimir
432
3452
Boring
None
Xi
Billy
Joe
261
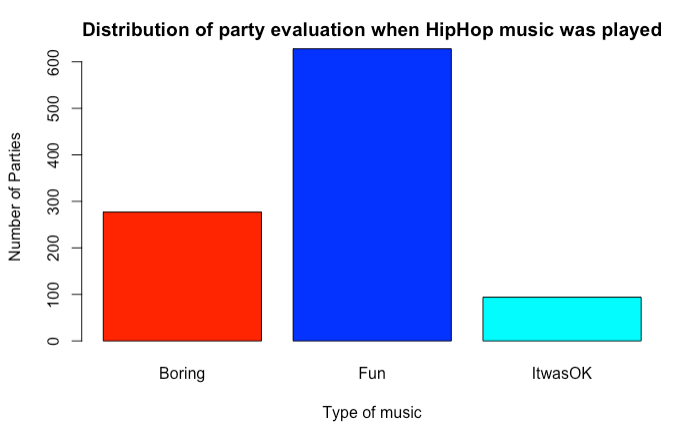
Figiure 2: Distribution of party evaluation when HipHop music was played 14.3.2.6
14.3.1 🧙 Secret patterns embedded by the Data Maker (hint)
When Vladimir is not at a party it is much more likely to be Fun. On the other hand with Angela…parties are almost always boring. She seems to be the life of a party! Music plays a role as well, when HipHop is played and is catchy (people are dancing) than party rocks. Without any music, the party tends to be just OK. Alex is a good host, provided he plays classical music. This must be an older crowd though?
Q: Verify the hypothesis that there is more dancing at Fun parties than at Boring parties? A: Positive. We reject null hypothesis that there is same amount of dancing at Fun and Boring parties with p < 0.00001
You are now familiar with the Party dataset and it’s time to give your understanding a test. Please click the link below to get to the quiz and come back here to cross-check your answer in the snippet 14.3.4.
In local elections in some small towns, candidates of three local parties: Royalists, KnowNothings and Anarchists are running for the office of the mayor. DataMaker has generated a survey of thousands of town residents and their political sympathies. Data of course can not be more local, leaving global concerns such as inflation or global warming to national or state office candidates.
Here, the electorate cares about issues such as “should we allow leaflowers” (all, only electric, none?), what about CBD stores in town (none, just one, no restrictions), How about liquor (should the town be dry? Or hard liqueurs only). Speed limits? (none, 10mph etc) or even more extreme - the whole town being car-free, streets open only to bicycles and pedestrians?
Can we develop the profiles of voters for each of the parties? What does the anarchist electorate care about? Which party is leading among young people who do not want any speed limits in town?
Table 14.3: Snippet of Voting Dataset
LeafBlowers
CBD
GasMowers
Party
LiquerStores
SpeedLimit
Age
41
NoRestrictions
OneStore
ElectircOnly
Royalists
None
NoLimits
94
794
NoRestrictions
NoStores
None
KnowNothings
HardLiquerOnly
25mph
65
2923
NoRestrictions
NoStores
None
KnowNothings
HardLiquerOnly
25mph
32
3900
NoRestrictions
NoStores
ElectircOnly
Royalists
None
NoCars
99
3592
None
NoStores
NoRestrictions
Anarchists
None
NoCars
44
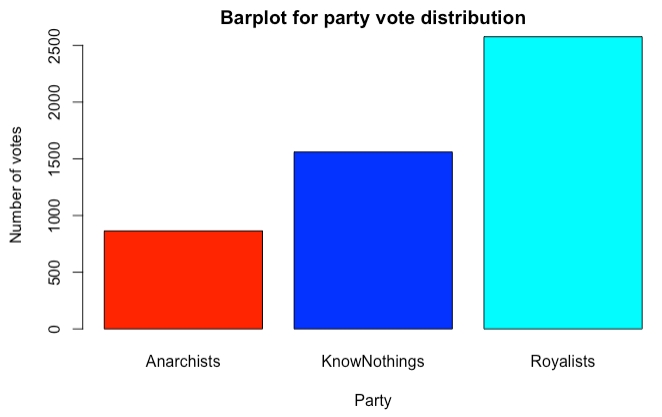
Figiure 3: Barplot for party vote distribution 14.4.2.12
14.4.1 🧙 Secret patterns embedded by the Data Maker (hint)
In this local town elections where issues are very…local. Nobody cares here about wars, oil or tariffs with China. Issues of importance are leaf blowers (electric only? Not at all), mowers, SpeedLimit (none? 5mph, no cars at all?)CBD and Liquor stores in town? From a completely dry town to no restrictions whatsoever.
The radicals who want no speed limits and no restrictions on leaf blowers as well as opening CBD stores anywhere you want, predictably mostly vote for Anarchists. There is a local electorate strongly devoted to KnowNothings (this old party has resurrected itself in this small town).. There are voters who like Liquor stores to serve hard liquor only (real alcohol, no wimpy beers, wines) and voters who believe in very tight speed limits (below 5mph)!. Seniors (Age >65) tend to vote Royalists. What does it mean to be a Royalist in a small town only? Good question. We guess the office of mayor is inherited and belongs to the local blue bloods?.
Q: Verify the hypothesis that the average age of Anarchists voters is higher than the average age of KnowNothings voters? A: Positive. Reject of null hypothesis that average ages of Anarchists and KnowNothings voters are the same
Q: What is the most frequent position of Anarchists on the Speed Limit issue? A: “No limits” is the most frequent position of Anarchists on Speed Limit issue
You are now familiar with the Election dataset and it’s time to give your understanding a test. Please click the link below to get to the quiz and come back here to cross-check your answer in the snippet 14.4.4.
Who wouldn’t want to know the secrets of good sleep? DataMaker has created a data set which may help to find these secrets. We store the number of exercise calories burnt during the day, the amount of wimpy tea a person has drunk (in ounces), hours spent on the computer and the quality of the preceding night’s sleep.
Table 14.4: Snippet of Sleep Dataset
Sleep
ExerciseCal
OnComputer
WimpyTea
RoomTemp
Moon
LastSleep
1497
Deep
928
6
3Cups
70
Dark
Shallow
186
Deep
272
8
3Cups
70
Dark
Deep
1482
Shallow
40
5
1Cup
73
Dark
Deep
562
Deep
478
7
1Cup
63
Half
Shallow
704
Little
987
1
3Cups
60
Full
Deep
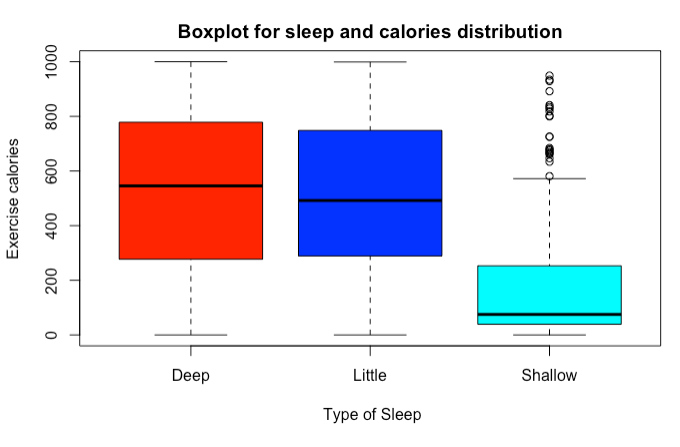
Figiure 4: Boxplot for sleep and calories distribution 14.5.2.6
14.5.1 🧙 Secret patterns embedded by the Data Maker (hint)
Insomnia (no sleep) occurs when the moon is full and there is a significant amount of exercise (above 300 Cal). Even when there was little exercise the full moon has a very negative influence on sleep - “Little” is the quality of sleep with full moon and with less than 300 calories spent exercising.
The secrets of deep sleep are scattered. Cold room and many cups of wimpy tea do the trick. Also, deep sleep comes when last night’s sleep was shallow and a significant number of hours were spent on the computer!
Q: What are the odds of Deep sleep when last day’s sleep was Shallow? A: Posterior Odds= 15.27 (probability = 0.93!)
Likelihood Ratio = 5.25
Prior Odds = 2.91
Q: Verify hypothesis that deep sleepers spend on average more time on the computer than Shallow sleepers? A: Negative. Fail to reject null hypotheses that means are the same.
You are now familiar with the Sleep dataset and it’s time to give your understanding a test. Please click the link below to get to the quiz and come back here to cross-check your answer in the snippet 14.5.4.
Using DataMaker we have started with the imdb data set from Kaggle and embedded some patterns in it. The original data set contains data about 12,800+ movies. We have expanded this data set by DataMaker’s opinions. Yes, only DataMaker can have an opinion on each of 12,800 movies! Can you predict which movies does DataMaker love and which movies bore him so much that she quit? What movies DataMaker passionately hates (hmm is DataMaker even passionate about anything at all?).
When does DataMaker agree with the imdb score?
Can one predict an imdb score on the basis of a combination of DataMaker opinion (sort of super critic) and other attributes?
Table 14.5: Snippet of Movies Dataset
country
content
imdb_score
Gross
Budget
genre
5345
UK
R
7.84
Medium
Medium
Drama
7028
USA
PG
5.89
Medium
Medium
Comedy
5222
USA
PG-13
6.33
High
Medium
Comedy
8283
UK
R
6.97
Medium
Medium
Action
535
USA
PG
6.23
High
High
Family
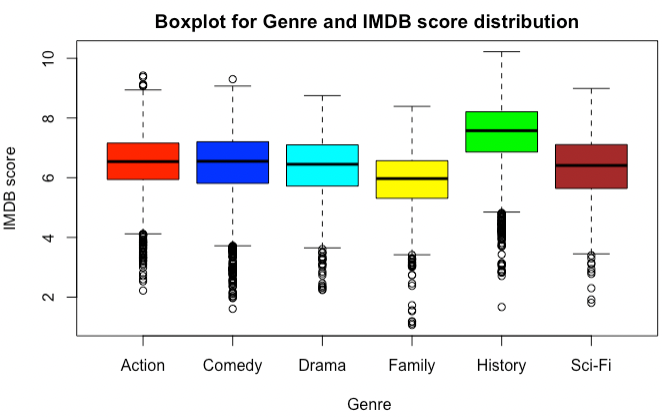
Figiure 5: Boxplot for Genre and IMDB score distribution 14.6.2.9
14.6.1 🧙 Secret patterns embedded by the Data Maker (hint)
The documentaries (History) have a tendency to have higher imdb scores. The high gross Comedies do not get appreciated by imdb. And there are also patterns which link high gross movies to genre and content rating. They are easy to discover. Try!
You are now familiar with the Movies dataset and it’s time to give your understanding a test. Please click the link below to get to the quiz and come back here to cross-check your answer in the snippet 14.6.4.
You are all familiar with Canvas, right? This is where you look to see your grades for each assignment and exam. This is where you see the scores. However it seems that Canvas went a bit wild and unfair in this data set.One can still fail the class with the score of 82 (sounds familiar, yes, Professor Moody would do it, but Canvas?
How can one get a lower grade with a higher score?
Yes, Canvas was instructed by someone and your goal is to discover the grading method. How to get an A, how to pass? We know who that someone is… it is DataMaker of course.
Table 14.6: Snippet of Canvas Dataset
Homeworks
Exams
Score
Grade
197
30
7
27.7
F
1865
57
86
59.9
C
623
83
74
82.1
A
868
68
63
67.5
B
1835
30
2
27.2
F
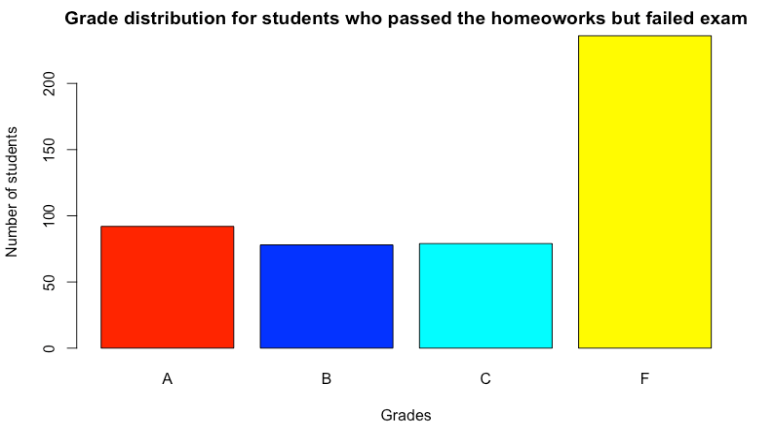
Figiure 6: Grade distribution for students who passed the homeoworks but failed exam 14.7.2.8
14.7.1 🧙 Secret patterns embedded by the Data Maker (hint)
Canvas allows professors to build linear formulas to provide weights for homeoworks, projects and exams and calculate the final score which is then mapped to grades, the usual; way, say A is over score of 90, B over score of 75 etc. This canvas method however has also a decision tree embedded addressing rare but troubling cases when a student’s score was very high on homoworks but low on the final exam. Even if the global weight of the final exam is small, say only 15%, the professor is concerned that if the score is very low on the final - say less than 20% of the maximum final score. Even if the overall score is in A range should such a student get an A?
The method here is very cruel and would for sure be objected to by many students :-). No matter how high your final score is, if your final exam is low, you may actually fail the class!
Check out what is the weight of the final exam? And what is the threshold of Fail, no matter what? Is there such a threshold that if your final exam score falls under it, you fail no matter what?
Q: Verify Hypothesis that Mean exam score for B students is higher than mean exam score for C students. What is the p-value? A: Negative. We fail to reject the null hypothesis with p=0.23
You are now familiar with the Canvas dataset and it’s time to give your understanding a test. Please click the link below to get to the quiz and come back here to cross-check your answer in the snippet 14.7.4.
A small local minimarket chain (think Wawa at its early days) has a few locations in New Jersey and it sells beer, snacks, sweets. DataMaker provided the data set of several thousand of transactions in the minimarket storing what items were purchased, when they were purchased (weekday or weekend) at which location.
Table 14.7: Snippet of Minimarket Dataset
Beer
Day
Location
SoftDrinks
Sweets
Wine
Snacks
10690
Lager
Weekday
Edison
Cola
Milky Way
Red
None
9450
Lager
Weekday
Princeton
Cola
Milky Way
Red
Pretzels
14090
None
Weekend
Metuchen
Cola
Snickers
Red
Pretzels
3302
None
Weekend
Metuchen
Cola
Milky Way
None
Crackers
9255
Lager
Weekend
New Brunswick
Sprite
Snickers
White
None
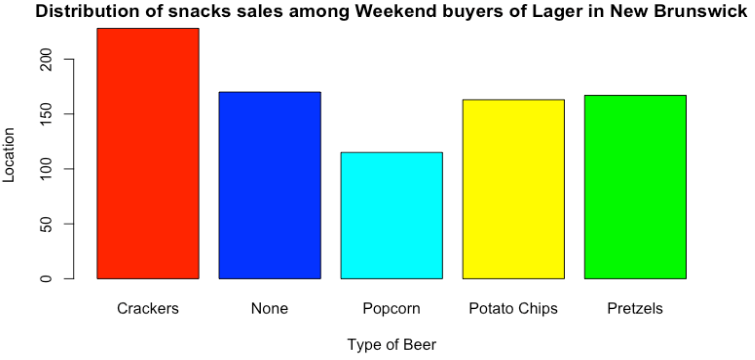
Figiure 7: Distribution of snacks sales among Weekend buyers of Lager in New Brunswick 14.8.2.5
14.8.1 🧙 Secret patterns embedded by DataMaker
Boundless analytics (last section) has discovered the embedded patterns in the mini market data. The golden pattern which was embedded was a subset of Lager buyers on the weekends in New Brunswick. These small subset of uses have a distinctly different distribution of snacks. Their taste for snacks is remarkably different among these transactions than the general distribution of snack sales over all transactions. There are many other associations similar to this one - for example Cola and Popcorn buyers in Princeton. We call these subsets - slices. There are many slices in this data which imply different distributions of snacks, sweets, soft drinks, wines, beers, locations and even weekday/weekend timing of the sale.
Q: Is distribution of purchases of snacks among Weekend buyers of Lager in New Brunswick different from base distribution of snacks? A: yes, very different
You are now familiar with the MiniMarket dataset and it’s time to give your understanding a test. Please click the link below to get to the quiz and come back here to cross-check your answer in the snippet 14.8.4.
Now it’s time for two real data sets - the airbnb data set and titanic sinking data set, both from Kaggle. These data sets have been cleaned before, this is why we do not have to spend our time on data wrangling!
The airbnb data set (Kaggle) stores around 30,000 plus data points about airbnb prices in NYC. We have modified the original set a little bit (we can’t stop!) adding the floor where the department is located to the existing attributes such as Room type, neighbourhood_group (boroughs), specific neighborhood and price.
Table 14.8: Snippet of Airbnb Dataset
id
name
host_name
neighbourhood_group
neighbourhood
room_type
floor
price
23849
34943918
Enjoy Brooklyn… visit Manhattan
Salomé
Brooklyn
Bedford-Stuyvesant
Entire home/apt
1
196.55355
33635
59709
Artistic, Cozy, and Spacious w/ Patio! Sleeps 5
Ricardo & Ashlie
Manhattan
Chinatown
Entire home/apt
1
285.73546
19865
766814
Adorable Midtown West Studio!
Caitlin
Manhattan
Hell’s Kitchen
Entire home/apt
1
284.20414
12700
9564986
Super Cozy Room in Floor Through Apartment
Sandy
Brooklyn
Williamsburg
Private room
1
97.79482
18024
30749411
Manhattan huge bedroom, with PRIVATE BATHROOM!
Francesco
Manhattan
Two Bridges
Private room
16
262.55557
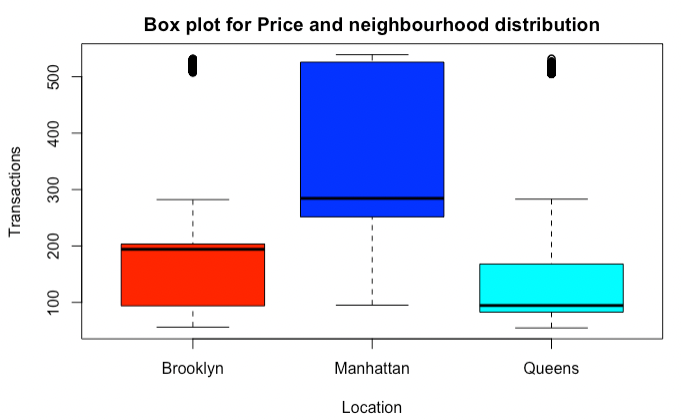
Figiure 8: Box plot for Price and neighbourhood distribution 14.9.1.6
You are now familiar with the Airbnb dataset and it’s time to give your understanding a test. Please click the link below to get to the quiz and come back here to cross-check your answer in the snippet 14.9.3.
The titanic data set (Kaggle) stores records of passengers of Titanic with attributes such as Survived, SibSp (family size), Fare, PClass (type of a cabin), Age etc. Here is a sample of data
Table 14.9: Snippet of Titanic Dataset
PassengerId
Survived
Pclass
Name
Sex
Age
SibSp
Parch
Ticket
Fare
Cabin
Embarked
715
715
0
2
Greenberg, Mr. Samuel
male
52
0
0
250647
13.0000
S
93
93
0
1
Chaffee, Mr. Herbert Fuller
male
46
1
0
W.E.P. 5734
61.1750
E31
S
624
624
0
3
Hansen, Mr. Henry Damsgaard
male
21
0
0
350029
7.8542
S
311
311
1
1
Hays, Miss. Margaret Bechstein
female
24
0
0
11767
83.1583
C54
C
586
586
1
1
Taussig, Miss. Ruth
female
18
0
2
110413
79.6500
E68
S
Figiure 9: Age distribution among survivors of Titanic disaster 14.10.1.7
Q: Verify hypothesis that survivors paid on average more for the ticker than those who did not survive? A: Positive. Null hypothesis rejected with p < 0.0001
Q: What is the probability of survival for passengers who paid more than 100 pounds for a ticket? How about those who paid less than 10 pounds? A: 0.73 for passengers who paid more than 100 pounds
0.20 for passengers who paid less than 10 pounds
0.38 for all passengers
You are now familiar with the Titanic dataset and it’s time to give your understanding a test. Please click the link below to get to the quiz and come back here to cross-check your answer in the snippet 14.10.3.